Turning 3D Models Into Search Vectors With Two Lines of CLIP
There is a two-line trick that turns a 3D mesh into a search-ready vector. Render the object from 8 angles, push each render through DINOv2, take the average. That is the whole pipeline. On a 200-object ModelNet40 subset I get 0.763 retrieval-precision@5 with mean-pool: three or four of every five top-5 nearest neighbours come from the same class as the query, without any 3D-specific architecture. Swap mean-pool for max-pool and the number climbs to 0.789.
This post is the bridge between rendering and searching. Everything in the series so far has been about getting clean pixels out of a mesh. From here on it is about what to do with those pixels. The thing I had to convince myself of, and want to show you, is that you do not need a 3D-native encoder to get a useful 3D search vector. You need a renderer and a 2D image encoder you can call as a function.
Here is the pipeline I will defend by the end of the post.
%%{init: {'theme': 'neutral'}}%%
flowchart LR
M[3D mesh] --> R[render 8 views]
R --> E[image encoder]
E --> V[per-view vectors]
V --> P[pool: mean / max / attn]
P --> O[one vector per object]
O --> I[FAISS index]
Q[query mesh] --> R
I --> N[top-k nearest objects]
Figure 1. The full pipeline. The same boxes show up in every Wave 2 and Wave 3 post in this series — the rest of the series is just swapping pieces in and measuring what changes.
The mesh comes in on the left. It is rendered from a fixed set of camera positions, each render becomes an image, each image becomes a vector through an off-the-shelf encoder, the per-view vectors are pooled into one per-object vector, and that vector is dropped into a FAISS index. At query time the query mesh goes through the same path. Nothing about the encoder knows or cares that the inputs are renders. CLIP and DINOv2 see what they always see: a 224×224 image, three channels, byte values.
This is the canonical primitive the series will reuse. Post 06 swaps the neural encoder for HOG and PointNet. Post 09 swaps "render 8 views" for voxel hashing. Post 11 stitches a real search engine around it. Each later post is one box in this diagram, traded in, with the rest held constant.
Eight views, one chair
Here is the render code, end to end. It uses the shared medium20.render_kit from Posts 01–02 — Post 01 ships load_canonical, Post 02 ships horizontal_ring and render_open3d.
Twelve lines, including imports, and you have an [8, 224, 224, 3] uint8 tensor ready to feed a vision transformer. The 8 cameras are evenly spaced on a horizontal ring at 20° elevation. The output looks like this.
Figure 2. Eight horizontal views of chair_0001 from ModelNet40, azimuth 0° through 315° in 45° steps. The plastic chair is fully described by the strip — front view, side view, back view, three-quarter views in between. Pulling the elevation up to 20° matters: a strict equator (0°) often hides the seat behind the back, and the encoder sees a vertical sliver.
Why 8 and not 1 or 32? One view loses too much; a chair from straight behind is a wireframe, a chair from straight above is a square. Past 16 views you are paying for marginal returns; the rendered side at azimuth=45° already covers what azimuth=44° would have shown. Post 11 has the actual ablation curve. For now: 8 is the empirical sweet spot for retrieval on object-scale shapes, and it keeps the per-object encode time under a quarter-second on a T4.
A second design choice that took me longer to settle than I expected: render in the same resolution the encoder wants. CLIP ViT-B/32 and DINOv2 ViT-B/14 both expect 224×224 inputs (CLIP via its preprocessor's resize-and-center-crop; DINOv2 via its AutoImageProcessor). Rendering at 1024×1024 and downscaling looks nicer in figures but adds nothing the encoder uses; the patch tokens are the same. I expected rendering at 224 to be dramatically cheaper than rendering at 1024; on the T4 the per-view cost goes from 15.2 ms at 224×224 to 20.0 ms at 1024×1024 (data/render-resolution-cost.csv), a 1.3× ratio, not the order of magnitude I had in my head. Open3D's per-frame setup dominates pixel shading on object-scale meshes. The argument for going straight to 224 is simpler: fewer bytes through every downstream step.
CLIP gives you a 512-dimensional vector per image, sitting in the shared image-text space where "a photo of a chair" lives nearby. DINOv2 gives you a 768-dimensional vector per image, the CLS token from a ViT-B/14 trained with self-supervision on a curated 142M-image dataset called LVD-142M. Neither knows what a chair is in the sense of having seen a "chair" label. CLIP knows what the word "chair" means; DINOv2 knows what photographs of chairs look like in a self-supervised feature space. They give different answers on real 3D queries.
A license note that matters if you ever ship this. DINOv2 weights are CC BY-NC: research only. For this blog and your own experiments it is fine; for anything customer-facing, swap in OpenCLIP or the original DINO. The code shape does not change; only the from_pretrained string does.
Per-view to per-object: pooling
Each object now has 8 vectors. You need 1. The simplest thing that works is to average them.
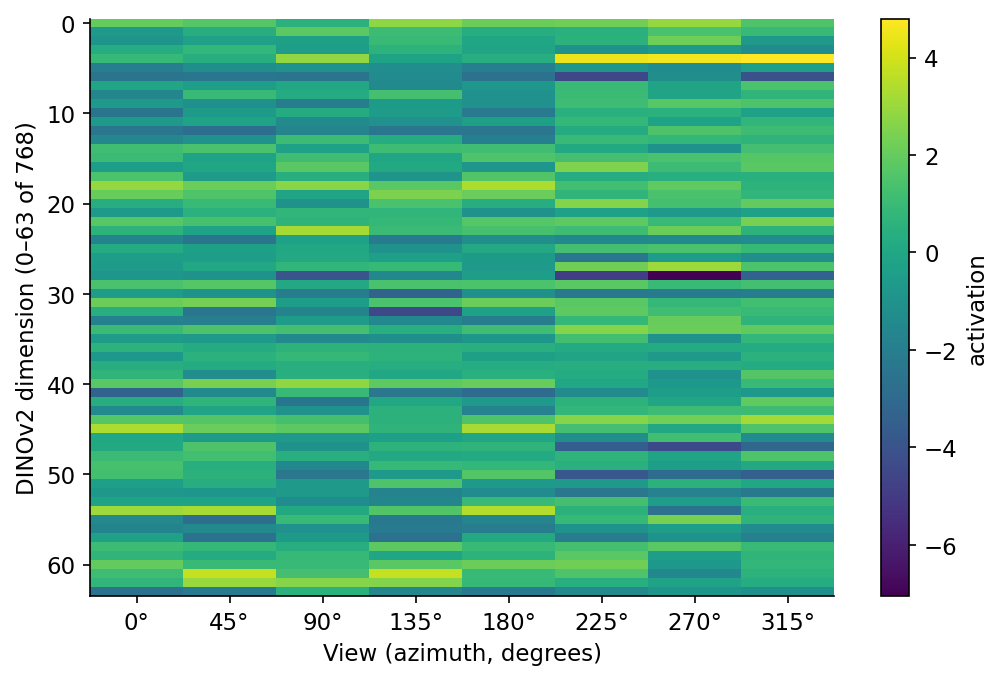
Six lines if you count the wrapper. Does it lose information? Almost everything in machine learning is "average a stack of representations until it works", so the prior is yes-but-not-much. Look at what the per-view embeddings actually look like before we collapse them.
Figure 3. DINOv2 activations for one chair across the 8 views, sliced to the first 64 of 768 dimensions. Horizontal bands — rows that stay roughly the same color across all 8 columns — are object-identity dimensions: they describe what the chair is, regardless of which side you are looking at. The dimensions that change column-to-column are viewpoint-dependent: they describe what part of the chair is facing the camera. Averaging across views damps the second group toward zero, which is exactly the point.
You can read the figure as "the encoder is already factoring object identity from viewpoint, and pooling finishes the job." That is roughly right and roughly enough.
Mean is the boring baseline. Max-pool takes the elementwise maximum across the 8 views, which is what you would use if you believed each dimension fires on a specific feature and the strongest fire is the signal. Attention-pool weights views by a softmax of a learned (or here, mean-derived) query vector and sums. I tried all three.
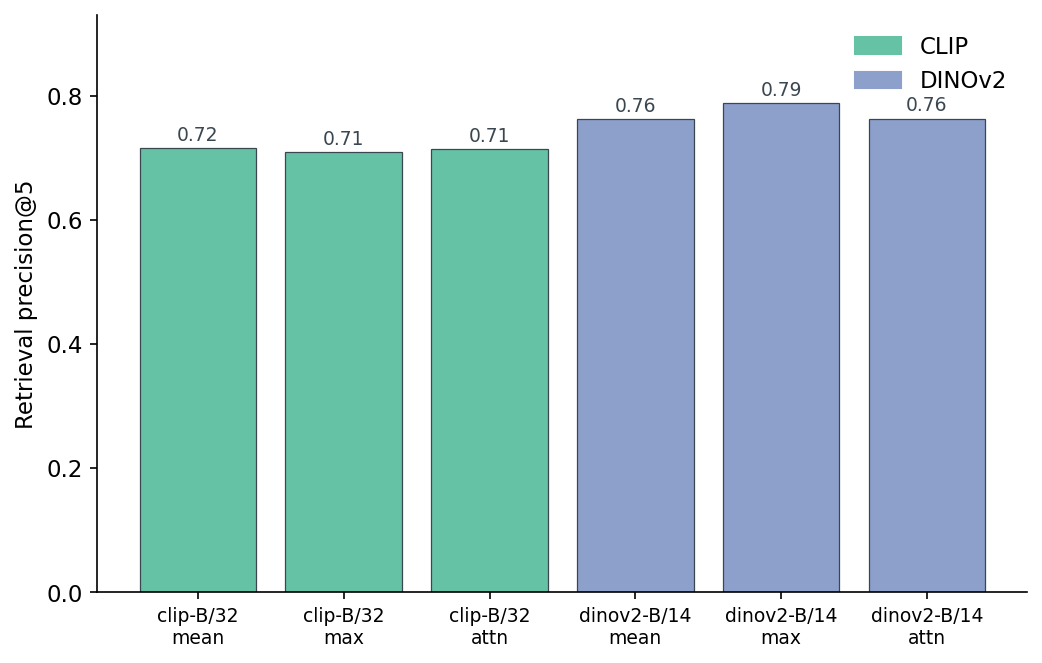
Figure 4. Retrieval-precision@5 by encoder and pooling method on the 200-object pool. DINOv2-max edges DINOv2-mean by 2.6 points; mean and attention land within a tenth of a point of each other in both encoders. The pooling method matters less than the encoder choice. The DINOv2 vs CLIP gap is roughly 6-8 points whichever pool you pick.
What stands out is what didn't move. Attention-pool was supposed to be cleverer than mean-pool — give the model a query vector, let it weight the views. It is, here, indistinguishable. Both DINOv2-attn at 0.764 and DINOv2-mean at 0.763 sit in the same place to two decimal points. Mean-pool wins on simplicity. Max-pool wins on the leaderboard by 2.6 points. For the rest of this post I will treat mean-pool as the default because it is the strongest result without adding any moving parts; if you wanted to chase the absolute number you would pick max.
Does it actually retrieve?
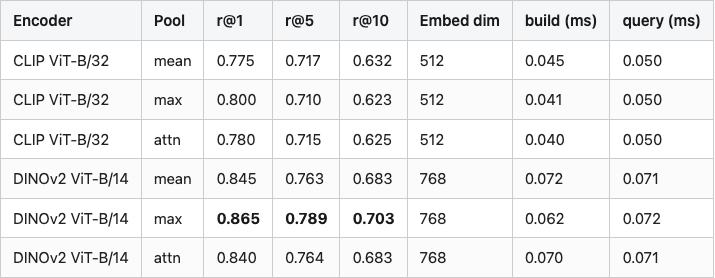
Table 1 has the full evaluation. The headline column is retrieval@5 — for every object in the 200-object pool, query the FAISS index with its pooled vector, look at the top-5 neighbours (excluding itself), and count what fraction share the query's class. Average across all 200 queries.
Table 1. Retrieval precision (within-class hit rate, excluding self) for six (encoder, pool) combinations on a 10-class, 200-object ModelNet40 subset. Index is FAISS IndexFlatIP over L2-normalised vectors. Best value in each column bolded.
Table 1
Source: data/retrieval-at-5.csv (6 rows).
A few things I want you to take away from the table. The DINOv2 vs CLIP gap is real and consistent: every DINOv2 row beats every CLIP row on every column. The pooling choice within each encoder is small noise; the encoder choice is the lever. r@10 always sits lower than r@5, because each class only has 20 objects total, so once you ask for the top 10 you are inevitably reaching into the other 180. The FAISS index itself is irrelevant at this scale: build is 70 microseconds, query is 70 microseconds. The work is in the encoder, not the index.
Pictures are more convincing than numbers. Here are the top-5 neighbours for three real queries.
Figure 5. Top-5 nearest neighbours under DINOv2-mean for a chair, an airplane, and a lamp query. Black titles are same-class hits; red titles are class mistakes. The chair query retrieves five chairs cleanly. The airplane query retrieves four airplanes and one guitar — the guitar happens to have a long thin neck and a wider body, which is roughly an airplane silhouette. The lamp query retrieves four lamps and one guitar — same explanation, the silhouette of a vertical neck on a base is shared between guitars and stand-style lamps.
The mistakes are educational. The encoder is not picking up "what is this object?"; it is picking up "what shape is this object?" An airplane in profile and a guitar in profile look quite similar, and the encoder agrees. This is something a 3D-native model would also have to learn its way around, but it is much more obvious when the encoder is image-based and you can read the silhouette as a shape signal directly.
Class structure: a t-SNE
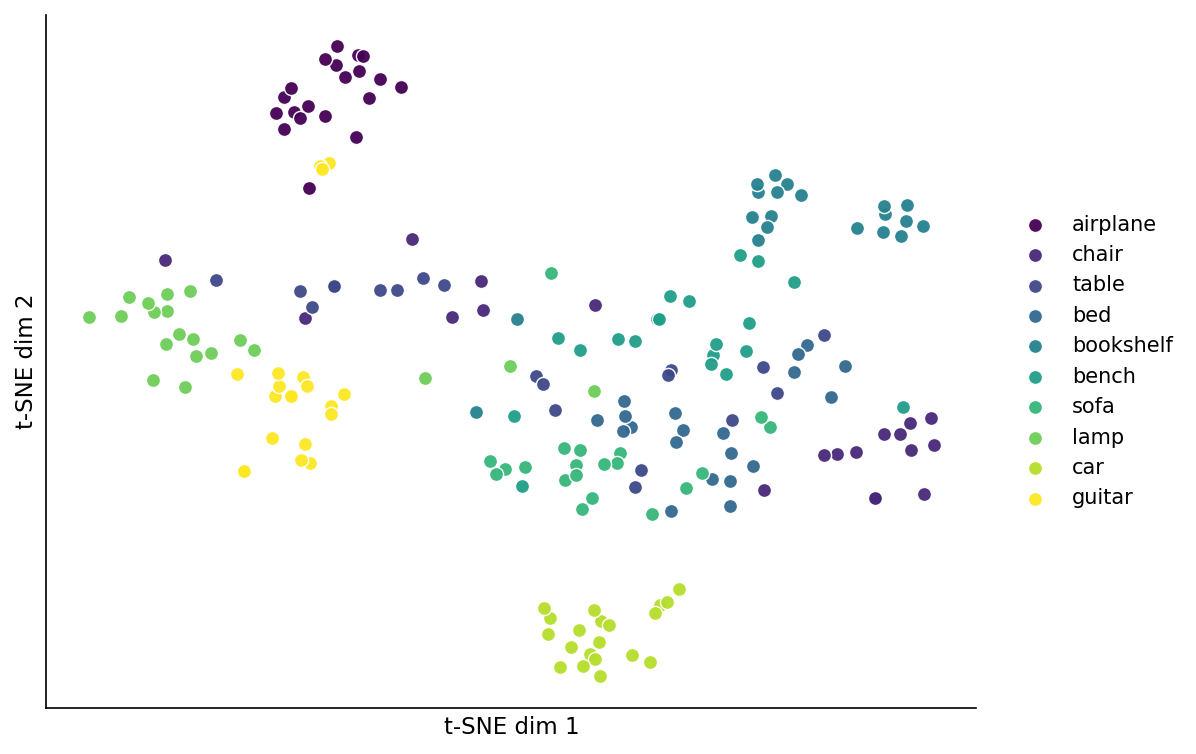
Project the 200 DINOv2-mean vectors down to 2D and colour by class, and the class structure pops out.
Figure 6. t-SNE projection of 200 DINOv2-mean object vectors, coloured by class with a Viridis-at-10 sampling. Airplane (dark purple, top), car (light green, bottom), guitar (yellow, left), and bookshelf (teal, right) form tight, well-separated clusters: these are the classes the model finds easy. The middle of the figure is a tangle of chair, bed, sofa, bench, and table — all flat-topped, four-cornered furniture that share a silhouette. Lamp sits to the left, distinct in shape from the furniture cluster. Perplexity 30, random_state 42.
t-SNE is decorative: it preserves local neighbourhood structure but not distances, and any "this cluster is far from that one" claim is suspect. The reason I am showing it anyway is that the local structure agrees with the retrieval numbers. The classes that cluster are the classes you can search for; the classes that tangle are the classes the encoder struggles to tell apart. Post 13 will make a similar projection with Sammon mapping, which actually does preserve distances, and the picture is messier. The same clusters survive.
CLIP vs DINOv2, side by side
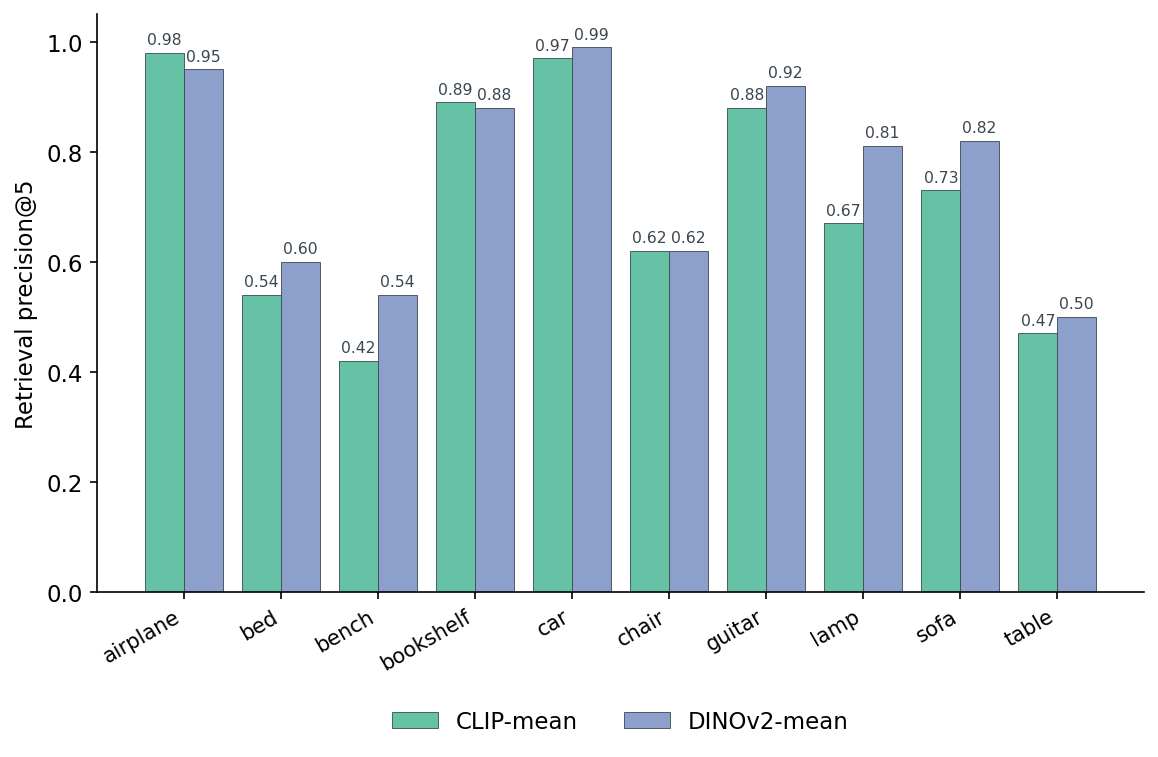
Here is the per-class breakdown for the head-to-head, both encoders mean-pooled.
Figure 7. CLIP-mean vs DINOv2-mean, retrieval-precision@5 broken down by class. The two encoders are roughly tied on the "easy" classes — airplane, car, bookshelf, guitar — where any half-decent vision model resolves the silhouette. The DINOv2 advantage shows up where the brief expected CLIP to win: lamp (0.81 vs 0.67, a 14-point gap), sofa (0.82 vs 0.73), and bench (0.54 vs 0.42). CLIP only edges DINOv2 on airplane (0.98 vs 0.95), it is a tie on chair (0.62/0.62), and a near-tie on bookshelf (0.89 vs 0.88).
I want to call out one thing in that chart that I genuinely did not expect. Going in, I had it in my head that CLIP would win on the texture-y / colour-y classes — lamps with metal shades, sofas with fabric — because CLIP was trained on captioned web images where colour and material show up in the text. DINOv2, with no language signal, would be "shape-only." The data says the opposite: DINOv2 wins lamp by 14 points and sofa by 9, both classes where shape is the harder problem because there is real intra-class variation. DINOv2's self-supervised features generalise better to silhouettes the model never saw at training time, even compared to a model that saw labelled web text including the word "lamp."
So when should you pick which? The decision tree is short.
%%{init: {'theme': 'neutral'}}%%
flowchart TD
Start[need a 3D embedding] --> Q1{need text alignment?}
Q1 -- yes --> CLIP[CLIP ViT-B/32]
Q1 -- no --> Q2{want best shape recall?}
Q2 -- yes --> DINO[DINOv2 ViT-B/14]
Q2 -- no --> Q3{need lowest latency?}
Q3 -- yes --> CLIP
Q3 -- no --> DINO
Figure 8. Encoder choice. If you need text-image alignment (zero-shot classification by typing class names, or cross-modal search), CLIP is the only option. If you want the best shape-only retrieval, DINOv2 wins. If you need the lowest per-image latency or the smallest embedding (512 vs 768), pick CLIP.
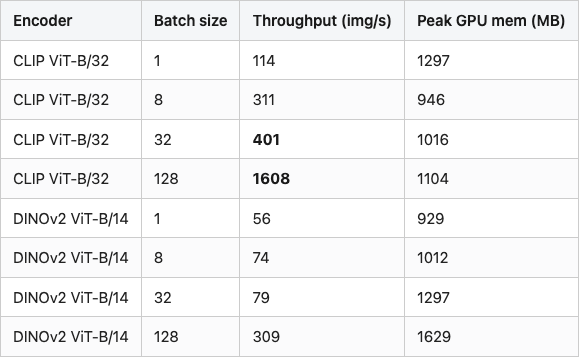
The latency case is real and is the second most useful result in this post. CLIP is dramatically faster than DINOv2 at every batch size.
Table 2. Encoder throughput on a Tesla T4, batch sizes 1 / 8 / 32 / 128, 224×224 input. CLIP ViT-B/32 runs ~5x faster than DINOv2 ViT-B/14 at every realistic batch size. Throughput is images per second, measured end-to-end including preprocessing.
Table 2
Source: data/latency-by-batch.csv (8 rows).
The 5x gap is mostly the patch size: CLIP ViT-B/32 has 32-pixel patches, DINOv2 ViT-B/14 has 14-pixel patches. Smaller patches mean a longer token sequence (49 vs 256 tokens for a 224×224 input), and transformer attention is quadratic in the sequence length. You pay for DINOv2's finer-grained features in compute. For a million-object ingest, that ratio is the difference between half a day and three days.
What you walked out with
A 3D model becomes a search vector in about 80 lines of Python: the render kit, two from_pretrained calls, a mean over the view axis, and a FAISS index. On a 10-class ModelNet40 subset, DINOv2 mean-pooled over 8 horizontal views gets you 0.763 retrieval-precision@5; max-pooled gets you 0.789. CLIP runs five times faster at the cost of about 7 points of retrieval precision. Whichever you pick, the canonical pipeline diagram in Figure 1 does not change.
The honest caveat is that this whole exercise has been "render once, encode once" on objects sitting upright in their canonical pose. Real 3D pipelines see meshes that have been rotated, scaled, decimated, and re-textured by whoever exported them. Post 06 is the bakeoff: take this same DINOv2-mean pipeline, rotate every query by a random angle, and benchmark it against five classical rotation-invariant descriptors that never see a neural network. The headline DINOv2 number does not survive — and the surprise is which classical descriptors do.
Reproducibility
All experiments run on a Tesla T4 in a conda env called 3d-dedup on AWS Lightsail. The shared kit is at medium20==0.1 (Post 02 build). The 200 objects are the first 20 entries (alphabetically by filename) from each of 10 classes in the ModelNet40 official train split. Total wall-clock for the experiments in this post: about 5 minutes. That covers 105 seconds to render 1,600 views, 4 seconds for CLIP encoding, 20 seconds for DINOv2, and the rest is the pooling/retrieval/t-SNE sweep.
Everything reported is a single deterministic run. PyTorch ops are deterministic on this T4 setup and t-SNE is seeded (random_state=42); the attention-pool uses a fixed-seed query (seed=0). I did not measure variance across reruns. The retrieval-precision numbers reproduced exactly on the second invocation.
Experiment configuration:
Table 3
Reproducibility checklist (every numeric claim in prose):
Table 4
Run:
conda activate 3d-dedup
cd posts/05-pixels-to-embeddings-clip-dinov2-primer
python code/main.py # full experiment, ~5 min on T4
python code/make_visuals.py # regenerates images/
DINOv2 weights are CC BY-NC (research-only). ModelNet40 is CC BY-NC (Wu et al. 2015). CLIP weights are released under the MIT license.